ICML 2023
https://proceedings.mlr.press/v202/dubois23a.html
 \
\
Introduction
문제정의
-
why or when a model is better,nor how to improve it
-
What are the major sources of errors in current SSL methods?
-
Are there tradeoffs between SS l SSL models across different settings (e.g. full- vs few-shotprobing)?
-
How does each design choice affect the SSL model?
-
Those are difficult to answer using a single metric.
-
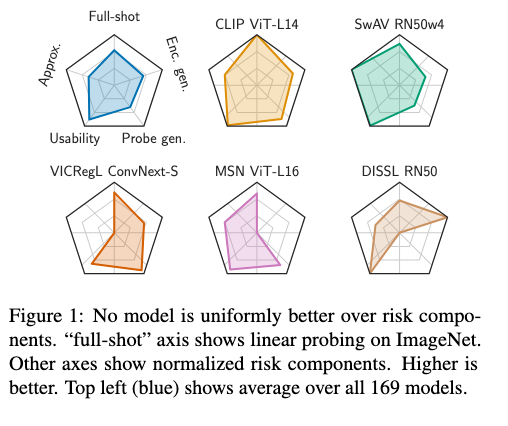
Our results provides insights into the state of the field, help understand design choices, and suggest which SSL encoder to choose in various settings.
Approximation (근사화) Approximation은 어떤 것을 다른 것으로 대체하는 것을 의미 이 때, 대체하는 것은 원래의 것과 비슷하지만 완벽하게 같지 않음 예를 들어, 원주율 π를 3.14로 표현하는 것이 근사화의 예시 사용되는 상황: 복잡한 수학적 식이나 함수를 더 간단한 형태로 바꿔 계산을 용이하게 하는 경우 복잡 → 단순화
Estimation (추정) Estimation은 불확실한 값을 추론하는 과정을 의미. 이는 관측되지 않은 값을, 주어진 데이터를 바탕으로 예측하는 것을 포함 예를 들어, 전체 인구의 평균 소득을 알기 위해 일부 샘플 데이터를 사용하여 전체의 평균을 추정하는 경우가 있음 불확실한 값 → 추론
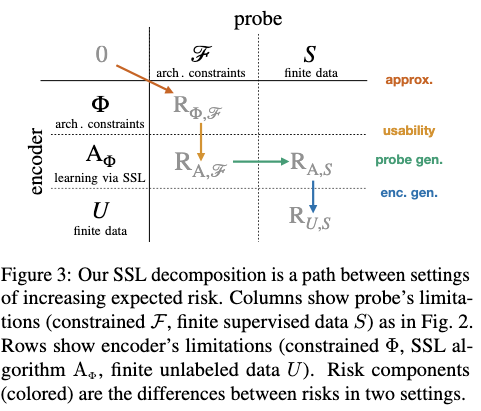
Our decomposition consists of four sources of errors:
- approximation errors due to the encoder’s architecture not having the capacity to perform the task;
- representation usability errors due to using SSL followed by linear probing. Usability error is large if a given SSL algorithm fails to produce linearly separable representations that can be used to predict desired tasks;
- probe generalization errors due to finite training data;
- encoder generalization errors due to pretraining the encoder on finite data.
-
Our analysis highlights that the most important source of error used to be the representation usability but, since SimCLR, it is now the probe generalization.
-
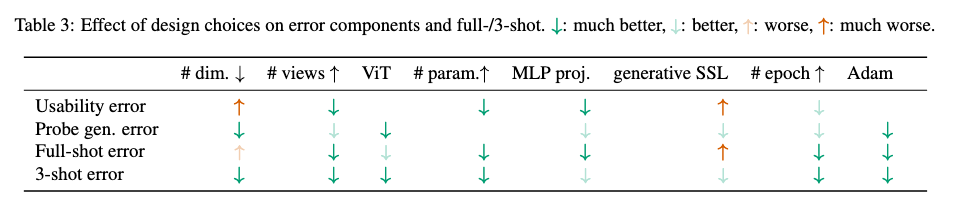
Furthermore, we show that some design choices (e.g. large projection heads, ViT encoders) improve all error components simultaneously.
-
But others (e.g. representations’ dimensionality or SSL objective) trade off components and thus only help in specific settings
Contribution
-
provide an SSL risk decomposition with an efficient estimator for each error component;
-
show that the main source of error for modern SSL is the generalization error of linear probes;
-
highlight a tradeoff between usability and probe generalization, which leads to a few- vs full-shot tradeoff;
-
analyze how 30 design choices affect the risk components and full-/few-shot performance of 169 SSL models.
Supervised risk decomposition
용어 정리
: model family : model familiy 중에서 특정 알고리즘 : 을 S의 데이터 셋으로 학습한 predictor (probe) = = 데이터셋 S에서 의 평균 loss 모델 들 중에서 가장 작은 error값
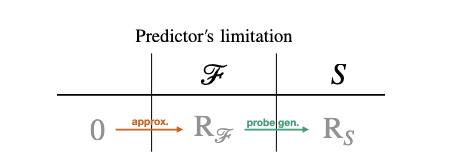
Supervised learning의 risk
- Approximation error : 무한한 데이터가 주어졌다고 가정하고, 특정 모델 구조가 선택되어 학습될 때 모델이 가지는 한계에 의한 오류. 매우 복잡한 함수가 있을 텐데, 우리는 그걸 단순화해서 어떤 모델로 한정짓고 단순화해서 해결하고자 함.
- Estimation error: 제한된 데이터로 발생하는 오류. 만약 무한히 데이터가 있었다면 에러가 10이었을 텐데, 데이터 부족으로 30이 되어버림 데이터가 부족해서 맞출 수 있는 성능이 부족함.
SSL risk decomposition
용어정리
: encoder familiy : encoder algorithm : encoder model : unsupervised data dist (가능한 모든 데이터의 이론적 분포) : unsupervised dataset

- encoder와 predictor (probe)를 결정함으로써 생기는 오류
- 모델의 capa가 증가하면 작아짐

-
SSL 파이프라인(, )을 통해 학습된 표현들이 지도 학습을 통해 얻은 표현들보다 덜 유용할 때 발생하는 오류를 측정합니다.
-
만약 SSL 알고리즘이 프로브(F, 예: 선형 프로브)가 사용할 수 있는 정보(예: 선형적으로 분리 가능한 클래스)를 유지하도록 보장한다면, 이 오류는 작아질 것입니다.
-
가용성 오류는 (!) SSL 알고리즘이 얼마나 잘 분리 가능한 표현을 생성하는지를 평가합니다.
-
이는 모델이 훈련 데이터의 특징을 얼마나 잘 포착하고 유용한 방식으로 표현하는지를 나타냅니다.
-
낮은 가용성 오류는 모델이 훈련 데이터에 잘 맞추어져 있으며(편향이 낮음), 따라서 전체샷 설정에서 더 나은 성능을 보일 수 있음을 의미합니다.
-
! 직관적 이해 : 비슷해 보이는 것들은 어느 정도 나뉠 수 있게 구분해 놓았음. 새로운 데이터에 대한 robust와는 상관없이.

-
**이 오류는 Probe를 유한한 샘플 집합 S에서 훈련시킬 때, 이상적인 샘플 집합 에 비해 성능이 감소하는 것을 측정합니다.
-
이 오류는 훈련 샘플의 수 |S|가 많거나, 표현이 프로브의 효율적인 샘플 사용을 보장할 때(예: 같은 클래스의 예시 간 마진을 최소화함으로써) 작아집니다.
-
이 오류는 모델이 (!)학습한 표현(representation)을 바탕으로 새로운, 보지 못한 데이터에 대해 얼마나 잘 일반화하는지를 나타냅니다.
-
특히, SSL에서는 프로브(즉, 추가적인 분류기 또는 회귀 모델)가 학습된 표현 위에서 훈련되어, 이 프로브가 새로운 데이터에 대해 얼마나 잘 예측하는지를 측정합니다.
-
프로브 일반화 오류가 낮다는 것은 모델이 제한된 훈련 데이터에서도 잘 일반화할 수 있음을 의미하며, 즉 모델의 분산이 낮다는 것을 의미합니다.
-
! 직관적 이해 : 어떤 새로운 데이터가 들어와도 일단 모델이 생각하는 공간 안에서 mapping됨. 갑자기 생뚱 맞은 feature 값을 내뱉지는 않는다는 의미.

- 이 오류는 인코더를 유한한 샘플 집합 U에서 사전 훈련시킬 때, 전체 인구 에 비해 성능이 감소하는 것을 측정합니다.
- 이 오류는 사전 훈련에 사용되는 가 샘플 효율적인 경우, 또는 많은 사전 훈련 예시들이 있을 때(|U|) 작아집니다.

이론적 unsupervised error term
- 중요. Infinite data 는 train data = test data setting (appendix B 참고)
- empirical distribution assumption
- 애초에 우리가 이 세상 모든 데이터를 구할 수 없다고 판단하기 때문에 train을 하고 test를 나누어서 성능을 보는 것
- 그런데 만약 우리가 이 세상 모든 데이터를 학습할 수 있다면 test 데이터가 필요할까? Nope 그냥 거기서 학습해서 모델을 만드는 것이 가능함. (이상적으로)
- 그리고 이 세상 모든 데이터를 알 수 있다면 어떤 encoder나 probe를 쓰든 그 성능은 크게 차이가 없을 것이다.라는 전제도 필요함.
- 궁국의 encoder와 prob를 가지고 있었다는 가정 하의 그들의 오류. 그냥 encoder + probe를 (모든 데이터로 지도학습 및 평가: train=test)
- encoder (모든 데이터로 SSL:train+test ) + probe(모든 데이터로: train=test) : 일 때의 error
- encoder가 뭔가 하나로 고정(모든 데이터로 SSL:train+test) + probe(한정된 데이터: train =! test) : 일 때의 error
- encoder가 뭔가 하나로 고정(한정된 데이터: train =! test) + probe는 학습은 (한정된 데이터: train =! test) 일 때의 error
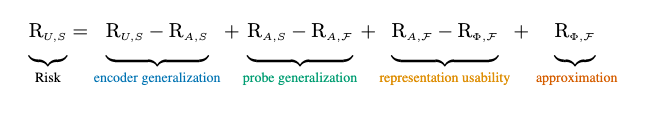
- 모든 encoder 중에 best의 성능과 현재 대상의 성능 차이
- 같은 encoder에서 best prob한데 데이터를 한정적으로 줬을 때의 성능 차이
- best prob는 고정되어있는데, best encoder와 현재 인코더의 성능 차이
- base가 되는 모든 걸 다 해봤을 때의 성능. (성능이 best가 되는 setting이므로 encoder+probe로 supervised.)
Estimating risk components for SSL
- Our goal is to compare pretrained SSL models using our decomposition.
- challenge
- pretraining additional SSL encoders is computationally prohibitive, so we want each of our estimators to use the same SSL encoder.
- This is a challenge because our risk components are defined using three different encoders (φ, φA, φU ).
- Our key insight is that we can estimate risk components by changing the training and evaluation set of the probe using the same pretrained SSL encoder.
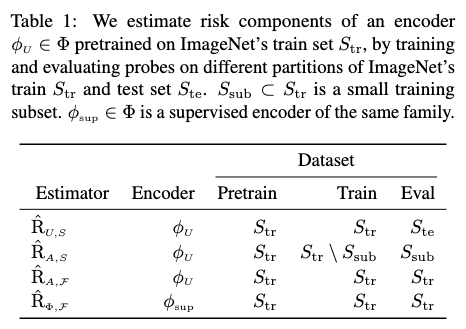
In the following, we illustrate this for the standard ImageNet SSL setting where the metric comes from pretraining encoders and training probes on the same inputs Str, and evaluating them on i.i.d. examples Ste. As a result, we can estimate risk components by training and evaluating probes on specific partitions of Str ∪ Ste as summarized in Table 1. We now provide the intuition behind each estimator. For formal derivations, properties, and pseudocode see Appx. B. As a reminder, the encoder is always pretrained on S_tr.
본적 있는 데이터로 test하는데도 틀리면 이건 모델 잘못 본적 있는 데이터로 학습하고 본적 없는 데이터로 평가했을 때 잘못한건 데이터 generation 잘못.
 인코더와 프로브 모두 유한한 데이터 집합에서 훈련될 때의 위험을 추정해야 합니다.
이를 위해 프로브를 S_tr에서 훈련시키고 S_te에서 평가합니다.
여기서 S_te는 인코더와 프로브의 사전 훈련 집합(Str)과 겹치지 않으므로, 이 두 모델 모두 본 적 없는 데이터에 대해 평가되는 것을 보장합니다.
인코더와 프로브 모두 유한한 데이터 집합에서 훈련될 때의 위험을 추정해야 합니다.
이를 위해 프로브를 S_tr에서 훈련시키고 S_te에서 평가합니다.
여기서 S_te는 인코더와 프로브의 사전 훈련 집합(Str)과 겹치지 않으므로, 이 두 모델 모두 본 적 없는 데이터에 대해 평가되는 것을 보장합니다.
 프로브가 유한한 샘플에서 훈련되고 인코더가 전체 인구에서 사전 훈련된 경우의 위험을 추정합니다.
(이게 우리가 논의했던 내용 중 하나!) LVSD환자 모두 포함해서 encoder 학습하고, probe 학습할 때 LVSD train/valid/test로 나누어서.
이를 위해 S_tr을 전체 인구 데이터의 대체 추정치로 사용하며, 프로브를 위해 훈련 집합 S_sub ⊂ S_tr과 테스트 집합 S_tr \ S_sub로 나눕니다.
이렇게 함으로써 프로브는 본 적 없는 데이터에서 평가되지만 인코더는 그렇지 않습니다
인코더 모델의
프로브가 유한한 샘플에서 훈련되고 인코더가 전체 인구에서 사전 훈련된 경우의 위험을 추정합니다.
(이게 우리가 논의했던 내용 중 하나!) LVSD환자 모두 포함해서 encoder 학습하고, probe 학습할 때 LVSD train/valid/test로 나누어서.
이를 위해 S_tr을 전체 인구 데이터의 대체 추정치로 사용하며, 프로브를 위해 훈련 집합 S_sub ⊂ S_tr과 테스트 집합 S_tr \ S_sub로 나눕니다.
이렇게 함으로써 프로브는 본 적 없는 데이터에서 평가되지만 인코더는 그렇지 않습니다
인코더 모델의
 인코더와 프로브 모두 전체 인구 분포에서 사전 훈련된 경우의 SSL 위험을 추정합니다.
이를 위해 동일한 사전 훈련, 훈련 및 평가 집합 S_tr을 사용하여 인코더와 프로브가 훈련된 데이터에서 평가되도록 합니다.
R_A,F는 따라서 프로브의 훈련 오류입니다.
인코더와 프로브 모두 전체 인구 분포에서 사전 훈련된 경우의 SSL 위험을 추정합니다.
이를 위해 동일한 사전 훈련, 훈련 및 평가 집합 S_tr을 사용하여 인코더와 프로브가 훈련된 데이터에서 평가되도록 합니다.
R_A,F는 따라서 프로브의 훈련 오류입니다.

SSL이나 유한 샘플을 고려하지 않고, 구성된 함수군 F ◦ Φ에서 가능한 최고의 예측자의 위험을 추정해야 합니다. 이를 위해 F ◦ Φ 아키텍처(예: ImageNet에서의 ResNet50)를 가진 지도 학습 모델의 훈련 오류를 사용합니다.
- : encoder와 probe가 제한된 데이터를 학습했기에 생기는 오류
- : encoder는 이 세상 모든 데이터를 학습하였고(즉, probe의 test dataset까지 알고 있음), prob는 제한된 데이터만 학습한 경우에 생기는 오류
- : encoder와 probe가 이 세상 모든 데이터를 학습했다고 생각하는 경우.
- : 완벽한 encoder와 probe가 있는 경우, 즉 완벽한 encoder는 encoder+probe의 supervised learning 성능과 같을 것이다.

Experimental results
5.1 Major sources of errors
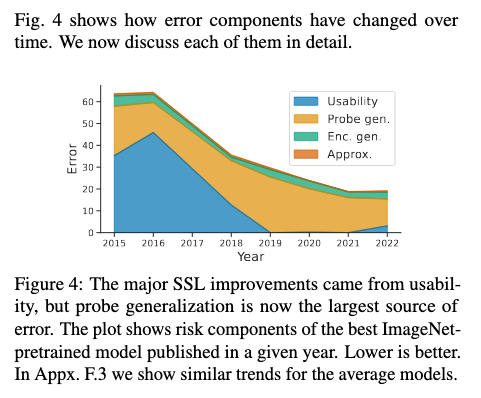
Usability drove improvements.
We see that usability used to be the largest source of error but it has improved steadily between 2016-2019. In Appx. F.3 we show that those improvements were mostly driven by the use and advances in contrastive learning
Probe generalization is now key.
We see that probe generalization is now the largest source of error, which suggests that it should be prioritized. For example, since 2019, the field has been able to improve overall performance by improving significantly this source of error.
Encoder generalization is small and constant.
We see that the encoder generalization has been relatively small over time but might become important in the near future. The fact that the generalization error is smaller for the encoder than the probe is surprising. Indeed, they are both (pre)trained on the same data (ImageNet’s training set) but the encoder is more “complex” than a regularized linear probe. This requires further analysis but could be due to overparametrization (Belkin et al., 2019; Yang et al., 2020).
Approximation error is negligible.
Unsurprisingly, current encoders have the capacity to perform the desired task.
For the rest of the paper, we focus on the most common sources of errors: usability and probe generalization.
5.2Tradeoffs affecting performance in various settings
Probe generalization signals sample efficiency.
- low probe generalization error perform → better in few-shot settings (less variance) 새로운 데이터에 probe가 문제없이 작동한다. 새로운 few-show 데이터에서도 잘 작동한다.
- low usability error perform → better in full-shot settings (less bias).
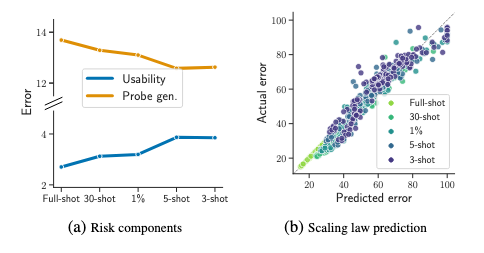
Usability/probe generalization tradeoff. Similarly to approximation/estimation, U/P is not an exact tradeoff but suggests that decreasing one tends to increase the other. This can be seen in Fig. 4: between 2016-2019 usability decreased at the expense of probe generalization, and viceversa since 2019. This can also be seen in Fig. 6: at every point in time, the best models seem to form a tradeoff curve.
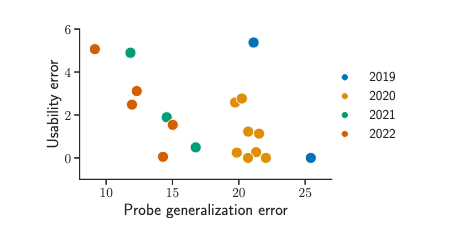
Full-/few-shot tradeoff.
- 가용성(Usability, U)과 프로브 일반화(Probe Generalization, P) 오류 사이의 관계와 그것이 전체샷(full-shot)과 소수샷(few-shot) 설정에서의 모델 성능에 어떻게 영향을 미치는지에 대해 설명하고 있습니다.
- 이러한 U/P 트레이드오프가 전체샷과 소수샷 설정에서의 모델 성능 트레이드오프로 변환될 것으로 기대합니다.
- 즉, 전체샷(100% 훈련 데이터) 설정에서 최고의 성능을 보이는 모델이 반드시 소수샷(예: 3샷) 설정에서도 최고의 성능을 보이지는 않는다는 것입니다. 이는 5가지 고려된 카테고리에서도 확인되며, 그림 5에서 이러한 현상이 U/P 트레이드오프에 의해 주도되고 있음을 제안합니다.
5.3 Analyzing design choices
 Q. 우리는 Usability error를 낮추고 싶은가 Probe generalization error를 낮추고 싶은가? 적은 데이터에서도 효과적인 encoder를 만들고 싶은가(prob gen)? 좋은 Base 모델을 만들고 싶은가(base gen)?
Q. 우리는 Usability error를 낮추고 싶은가 Probe generalization error를 낮추고 싶은가? 적은 데이터에서도 효과적인 encoder를 만들고 싶은가(prob gen)? 좋은 Base 모델을 만들고 싶은가(base gen)?
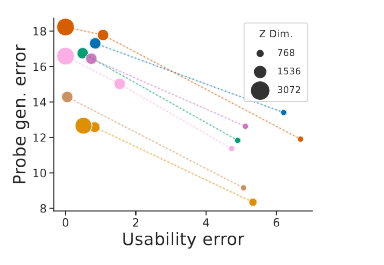
5.3.1 Dimensionality
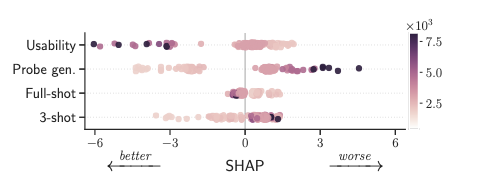
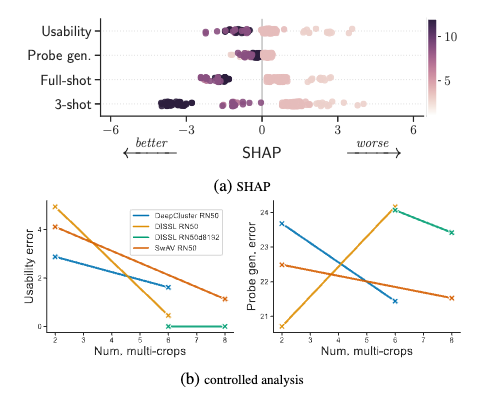
- Figure 7: Impact of the representation’s dimensionality (color) on the usability error, probe generalization error, and full-/3-shot linear probing. Impact is measured by SHAP values (x-axis). Lower is better as it decreases the risk.
- Increasing dimensionality improves usability at the expense of probe generalization.
- Moving along the U/P tradeoff without retraining.
5.3.2 Data and augmentations
- Augmentations improve usability and probe gen.
- Strengthening augmentations intuitively improves probe generalization by increasing the invariance of the SSL encoder, which will retain less information that probes can overfit t
5.3.3 Architecture
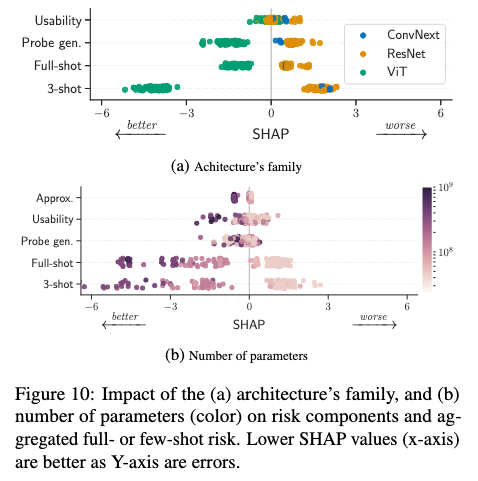
ViTs improve probe generalization. Fig. 10a shows that ViTs are significantly better than ResNets for probe generalization (GLA p-value=9e-8) and do not worsen usability. This thus translates to few- and full-shot improvements.
Larger encoders improve usability and approximation. Fig. 10b shows that increasing the number of parameters improves the usability and approximation (GLA p-value=4e-17), without impacting generalization. Those gains improve full- and few-shot performance. In Appx. D.3 we show that smaller ViT patch sizes lead to similar gains.
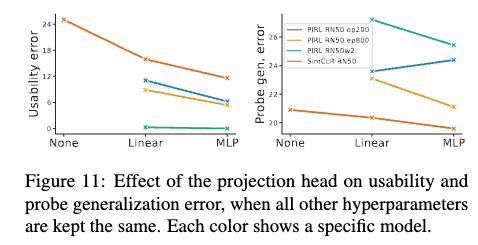
Large projection heads improve usability. Fig. 11 shows that MLP projections improve usability (CA p-value=9e-12) and often also probe generalization. In Appx. D.3 we show that increasing the capacity (number of parameters) of an MLP projection head further improves usability.
5.3.4 Objective
Generative and transformation-predicting objectives suffer from high usability error. The lack of usability explains why generative encoders such as MAE do not give a good linear probing performance, despite their strong fine-tuning performance Intuitively, generative objectives preserve all information about the input but do not ensure that this information is usable by linear probes In comparison, contrastive objectives ensure linear usability because they maximize dot-product similarity

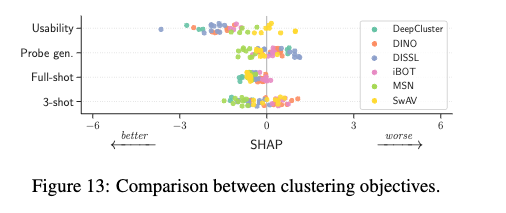
The exact objective has little impact.
This suggests that one should choose a simple and easy-totune objective and focus on other components.