참고문헌 (references)
- A Guide for Making Black Box Models Explainable
- Explainable Deep Learning Methods in Medical Diagnosis: A Survey
- A Review on Explainable Artificial Intelligence for Healthcare: Why, How, and When?
- Explainable Artificial Intelligence (XAI): What we know and what is left toattain Trustworthy Artificial Intelligence
- Training calibration-based counterfactual explainers for deep learning models in medical image analysis
- http://xai.kaist.ac.kr/Tutorial/2023/ Kaist tutorial series
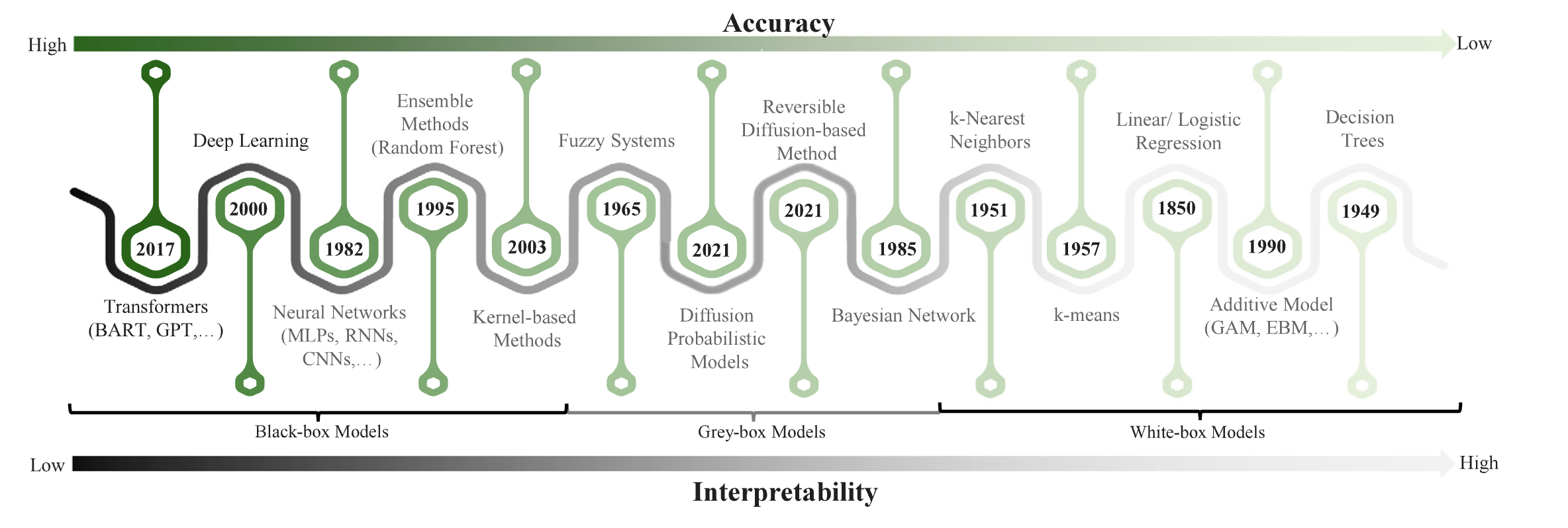
Introduction
interpretability(해석가능성) vs explainability(설명가능성)
-
Level of detail: Interpretability focuses on understanding the inner workings of the models, while explainability focuses on explaining the decisions made. Consequently, interpretability requires a greater level of detail than explainability. interpretability는 모델 내부 작동 자체에 대한 이해에 포커싱을 맞춘 반면에, explainability는 모델이 판단한 결정에 대해 해석하는 것에 좀 더 집중한다.
-
Model complexity: More complex AI models, such as deep neural networks, can be difficult to interpret because of their intricate structure and the interactions between different parts of the model. In these cases, explainability may be more viable, as it focuses on explaining decisions rather than understanding the model itself. 딥러닝의 경우에는 model complexity가 매우 높아, interpretability보다는 explainability에 좀 더 초점을 맞추게 된다.
-
Communication: Interpretability concerns the understanding of the model by AI experts and researchers, while explainability is more focused on communicating model decisions to end users. As a result, explainability requires a simpler and more intuitive presentation of information. interpretability는 AI전문가를 대상으로 한다면, explainability는 end user에게 설득하는 목적으로 사용된다.
-
내가 저 모델의 수식을 이해하면 동작원리를 어느정도 예측할 수 있다 → interpretability가 높은 모델이라고 할 수 있다.
-
==interpretable한 모델일 수록 explainable할 가능성이 매우 높아진다.== 그러나 deep learning과 같은 interpretability가 낮은 모델도 다른 방법들을 이용하여 explainability를 높일 수 있는 것이고 우리는 이것에 집중한다.

 (ref4.figure4)
(ref4.figure4)
(Why?) Importance of XAI
-
Human Curiosity and Learning: Humans update their mental models when faced with unexpected events, seeking explanations to understand and learn from these occurrences. Similarly, in research, interpretability in machine learning models is essential for uncovering scientific insights that remain hidden in purely predictive models.
-
Finding Meaning: People seek to resolve contradictions in their knowledge. When a machine’s decision impacts a person’s life significantly, it becomes crucial for the machine to provide explanations. 모델의 결정이 한 사람의 인생에 영향을 미칠 가능성이 클수록 설명은 더 필요해진다.
-
Scientific Goals: As various fields move towards quantitative methods and machine learning, models become knowledge sources. Interpretability allows for the extraction of this knowledge.
-
Safety Measures: In critical applications like self-driving cars, ensuring the model’s decisions are error-free and understandable is vital for safety.
-
Detecting Bias: Interpretability serves as a tool for identifying and correcting biases in machine learning models, ensuring fairness and compliance with ethical standards. 모델 자체가 가지고 있는 편향에 대해서 확인해야 한다. 특정 코호트(인구집단)에서만 성능이 좋은 것은 아닌지.
-
Social Acceptance: Interpretability increases the acceptance of machines and algorithms by providing explanations for their decisions, fostering trust and understanding. 특히, Healthcare 분야에서 의사들을 대상으로한 수용성을 높이기 위함.
-
Managing Social Interactions: Explanations from machines can influence human actions, emotions, and beliefs, facilitating smoother interactions between humans and machines.
-
Debugging and Auditing: Interpretability is essential for identifying and fixing errors in machine learning models, ensuring they function correctly and safely. 모델이 잘못 판단하고 있는 샘플들에 대한 디버깅. 그리고 모델 개선.
(What?) Concepts of XAI
-
Explainability: It involves making the workings of AI models transparent and understandable, aiming to bridge the gap between the complex decision-making processes of AI and human understanding.
-
Interpretability: This concept focuses on the extent to which a human can comprehend and predict the model’s behavior, making it easier for users to trust and effectively use AI systems.
-
Transparency: It emphasizes the need for AI models to be open about their operations, allowing users to see how and why decisions are made, thereby fostering trust and accountability. 모델이 개발되기까지의 과정이 모두 볼 수 있도록 개방되어있는가? 이 영역은 모델 설계부터 데이터 구성 및 학습과정 그리고 결정 근거까지 포괄한다.
-
Fairness: Concerned with ensuring AI decisions are impartial, non-discriminatory, and just, fairness is crucial for ethical AI applications, especially in sensitive areas like healthcare and law enforcement.
-
Robustness: This concept highlights the importance of AI systems being reliable and consistent under varying conditions, ensuring they perform accurately and predictably across different scenarios.
-
Satisfaction: Satisfaction refers to the degree to which users find the AI system’s explanations useful, relevant, and sufficient for their needs, impacting user acceptance and trust in AI technologies.
-
Stability: Stability involves the consistency of AI explanations, ensuring that similar inputs produce similar explanations, which is vital for user trust and understanding.
-
Responsibility: It encompasses creating AI systems that are ethically aligned, accountable for their actions, and designed with consideration for societal norms and values, promoting responsible usage and development of AI.
 (ref.4 figure 3) Relations among XAI concepts.
(ref.4 figure 3) Relations among XAI concepts.
Taxonomy of Interpretability Methods
-
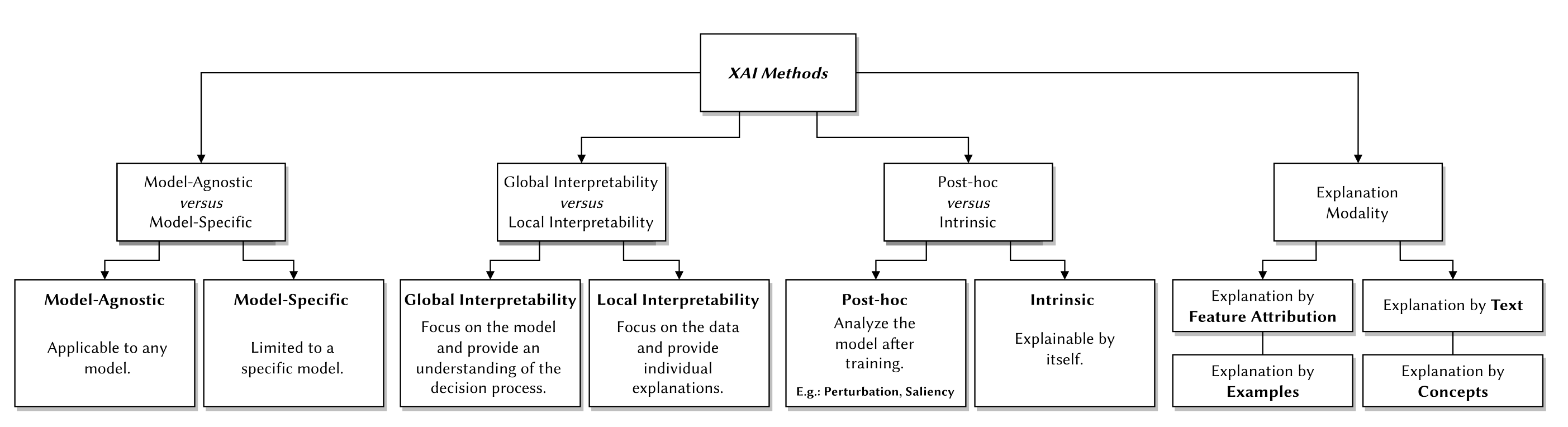
Intrinsic vs. Post Hoc:
- Intrinsic interpretability involves using models that are naturally interpretable due to their simple structure, such as short decision trees or sparse linear models.
- Post hoc interpretability refers to techniques applied after a model has been trained to analyze and explain its behavior. These methods can be used on both intrinsically interpretable models and more complex models.
-
Result of the Interpretation Method: Interpretation methods can be differentiated by their outputs, which include:
- Feature summary statistic: Provides summary statistics for each feature, like feature importance.
- Feature summary visualization: Visual representations of feature summaries, such as partial dependence plots.
- Model internals: Direct interpretation of model components, such as weights in linear models or the structure of decision trees.
- Data point: Methods that return specific data points (existent or newly created) to explain model predictions, like counterfactual explanations or prototypes of predicted classes.
- Intrinsically interpretable model: Approximating black box models with simpler, interpretable models to understand their behavior.
-
Model-specific vs. Model-agnostic:
- Model-specific tools are designed for specific types of models, such as linear models or neural networks, and often rely on the model’s internal structure for interpretation.
- Model-agnostic tools can be applied to any machine learning model and work by analyzing the relationship between input features and model outputs without needing access to the model’s internals.
-
Local vs. Global: Interpretation methods can also be classified based on their scope—whether they explain individual predictions (local) or the behavior of the entire model (global).
 (ref2.figure1)
(ref2.figure1)
Scope of Interpretability
-
Algorithm Transparency: This refers to understanding how an algorithm learns a model from data and the kind of relationships it can learn. It’s about the general workings of the algorithm rather than the specifics of the learned model or individual predictions.
-
Global, Holistic Model Interpretability: This level of interpretability is about comprehending the entire model at once, including its features, learned components (like weights or parameters), and how decisions are made. However, truly understanding a model globally is challenging, especially for models with many parameters.
-
Global Model Interpretability on a Modular Level: While fully understanding a complex model may be impractical, it’s often possible to understand parts of a model, such as the weights in linear models or the splits in decision trees. However, the interpretation of these components can be interdependent, making it difficult to isolate their effects.
-
Local Interpretability for a Single Prediction: This focuses on explaining why a model made a specific prediction for an individual instance. Local interpretations can sometimes offer more accurate explanations than global ones, as the model’s behavior for a particular instance may be simpler than its overall behavior.
-
(Glocal)Local Interpretability for a Group of Predictions: This involves explaining model predictions for a group of instances, either by applying global interpretation methods to the subset or by aggregating individual explanations.
Evaluation of Interpretability
-
Application Level Evaluation (Real Task): This approach involves integrating the explanation directly into the product and having it tested by the end user. For example, a machine learning system designed for detecting fractures in X-rays would be evaluated by radiologists to assess the model’s interpretability. This method requires a well-designed experimental setup and a clear understanding of quality assessment criteria, with human explanation capabilities serving as a baseline for comparison.
-
Human Level Evaluation (Simple Task): This is a simplified version of the application level evaluation, where experiments are not conducted with domain experts but with laypersons. This approach reduces costs and makes it easier to recruit a larger number of testers. An example could involve presenting users with different explanations for a model’s decision and asking them to select the one they find most understandable.
-
Function Level Evaluation (Proxy Task): This level of evaluation does not involve human participants. It is most applicable when the model class has previously been evaluated in a human-level evaluation. For instance, if it is known that end users find decision trees understandable, the depth of the tree could serve as a proxy for the quality of explanation, with shorter trees being rated as more interpretable. However, it’s important to ensure that the predictive performance of the model does not significantly deteriorate when simplifying it for the sake of interpretability.
Properties of Explanations
Properties of Explanation Methods
- Expressive Power: The complexity or simplicity of the explanations a method can generate, such as IF-THEN rules, decision trees, or natural language explanations.
- Translucency: The extent to which the explanation method relies on the internal workings of the machine learning model, such as its parameters.
- Portability: The ability of the explanation method to be applied across different machine learning models, with higher portability indicating applicability to a wider range of models.
- Algorithmic Complexity: The computational complexity of generating explanations, which is crucial when computation time is a limiting factor.
Properties of Individual Explanations
- Accuracy: The precision of an explanation in predicting unseen data, which is vital if the explanation is used for making predictions. 예시: 머신러닝 모델이 집값을 예측하는 경우, 모델의 설명이 “이 집의 가격은 큰 정원 때문에 높습니다”라고 할 때, 이 설명이 실제로 다른 집들에 대해서도 일관되게 적용되어 정원의 크기가 집값에 미치는 영향을 정확하게 반영한다면, 이 설명은 높은 정확도를 가진다고 할 수 있습니다. 설명 모델의 성능 자체가 좋은지 보통 설명을 위한 별도의 surrogate model이 있을 때.
- Fidelity: The accuracy with which the explanation approximates the prediction of the original model, highlighting the importance of the explanation’s relevance to the model’s decisions. 실제 모델과 설명 모델의 예측자체가 비슷한지
- 예시: 어떤 복잡한 머신러닝 모델이 특정 환자에게 약이 효과가 없을 것이라고 예측했다고 가정해 봅시다. 이 모델의 예측을 설명하는 데 사용된 간단한 결정 트리가 실제 모델의 예측 과정을 잘 반영하여, 왜 약이 효과가 없을 것으로 예측되었는지를 정확히 설명한다면, 이 결정 트리는 높은 충실도를 가진 설명이 됩니다.
- Consistency: The similarity of explanations across models trained on the same task and producing similar predictions, indicating the reliability of the explanation method. 예시: 두 개의 서로 다른 머신러닝 모델이 비슷한 예측 결과를 내놓았다고 합시다. 첫 번째 모델의 설명이 “이 환자에게 약이 효과가 없는 주된 이유는 고혈압 때문입니다”라고 하고, 두 번째 모델도 동일한 이유를 제시한다면, 이 설명들은 높은 일관성을 가지고 있다고 할 수 있습니다.
- Stability: The uniformity of explanations for similar instances, ensuring that minor variations in data do not lead to significantly different explanations. 예시: 어떤 집값 예측 모델이 비슷한 특성(예: 위치, 크기, 방의 수 등)을 가진 두 집에 대해 예측을 했다고 가정해 봅시다. 이 두 집에 대한 설명이 크게 다르지 않다면(예: “이 집의 가격은 위치 때문에 높습니다”), 이 모델의 설명은 높은 안정성을 가진다고 볼 수 있습니다.
- Comprehensibility: The ease with which humans can understand the explanations, which varies depending on the audience and is crucial for the practical utility of explanations. 예시: 머신러닝 모델이 복잡한 수학적 공식을 사용해 설명을 제공하는 대신, “이 집은 최근에 리모델링되어 가격이 높습니다”와 같이 일반인도 쉽게 이해할 수 있는 언어를 사용한다면, 이 설명은 높은 이해성을 가진다고 할 수 있습니다.
- Certainty: Whether the explanation reflects the model’s confidence in its predictions, providing insight into the model’s reliability. 예시: 모델이 어떤 환자에게 약이 효과가 있을 것이라고 예측하면서, 이 예측에 대한 확신도(예: “이 예측은 90%의 확률로 정확합니다”)를 함께 제공한다면, 이 설명은 모델의 확실성을 잘 반영하고 있다고 볼 수 있습니다.
- Degree of Importance: The explanation’s ability to highlight the importance of features or parts of the explanation, aiding in understanding the model’s decision-making process. 예시: 집값 예측 모델의 설명이 “이 집의 가격은 큰 정원과 최신 주방 때문에 높습니다. 그 중에서도 정원이 가장 큰 영향을 미칩니다”라고 특정 요소의 중요도를 명시한다면, 이 설명은 특성의 중요도를 잘 반영하고 있다고 할 수 있습니다.
- Novelty: The explanation’s indication of whether a data instance comes from a distribution far removed from the training data, affecting the model’s accuracy and the explanation’s usefulness.
- 예시: 모델이 훈련 데이터에 없던 새로운 유형의 집에 대한 예측을 할 때, “이 집은 우리 데이터에 없던 특이한 구조를 가지고 있어 예측에 불확실성이 높습니다”라고 설명한다면, 이는 신규성을 잘 반영하는 설명입니다.
- Representativeness: The scope of instances an explanation covers, ranging from explanations that apply to the entire model to those specific to individual predictions. 예시: 어떤 설명이 단지 한 두 개의 예측에만 적용되는 것이 아니라, 모델이 만든 모든 예측에 대해 일반적인 원리를 설명한다면(예: “이 모델은 주로 위치와 크기를 기반으로 집값을 예측합니다”), 이 설명은 높은 대표성을 가진다고 할 수 있습니다.
Methods
CAM based method
GradCAM
- Model specific, Local, Post-hoc, heatmap
- Grad-CAM(Gradient-weighted Class Activation Mapping)은 합성곱 신경망(CNN)의 결정 과정을 시각화하기 위한 기법 중 하나입니다. 특히, CNN이 이미지 내 특정 부분에 주목하여 클래스를 결정했다는 것을 시각적으로 이해할 수 있게 해줍니다. 이 방법은 모델의 마지막 합성곱 층에서 얻은 특징 맵(feature maps)에 대한 그래디언트 정보를 사용하여 해당 클래스에 대한 각 특징 맵의 중요도를 계산합니다.
Grad-CAM을 구현하는 과정은 다음과 같습니다:
-
목표 클래스에 대한 손실 함수의 그래디언트 계산: 먼저, 목표 클래스에 대한 손실 함수()를 정의하고, 이 손실 함수에 대해 마지막 합성곱 층의 출력 특징 맵()에 대한 그래디언트를 계산합니다. 여기서 는 특징 맵의 인덱스입니다.
-
특징 맵의 중요도 가중치 계산: 각 특징 맵에 대한 그래디언트의 글로벌 평균을 계산하여, 해당 특징 맵이 목표 클래스의 결정에 얼마나 중요한지 나타내는 가중치()를 얻습니다.
여기서 는 특징 맵의 차원을 나타내는 상수(너비 높이), 와 는 각각 특징 맵의 세로 및 가로 인덱스입니다.
-
가중치와 특징 맵의 선형 결합으로 클래스 활성화 맵 생성: 목표 클래스에 대한 각 특징 맵의 중요도를 나타내는 가중치()와 해당 특징 맵()을 곱한 후, 모든 특징 맵에 대해 합하여 클래스 활성화 맵(CAM, )을 생성합니다.
여기서 ReLU(Rectified Linear Unit) 함수는 음수 값을 제거함으로써, 모델이 클래스를 결정하는 데 중요한 영역만을 강조합니다.
Grad-CAM 방법을 통해 생성된 클래스 활성화 맵은 원본 이미지 위에 오버레이될 수 있으며, 이를 통해 모델이 특정 클래스를 인식하기 위해 이미지의 어떤 부분에 주목했는지 시각적으로 확인할 수 있습니다. 이 기법은 모델의 해석 가능성을 높이고, 모델이 올바른 근거로 결정을 내렸는지 검증하는 데 유용하게 사용됩니다.

Perturbation based Method
- Input에 변형(perturbation)을 가함으로써 모델의 판단근거를 해석하려는 방법
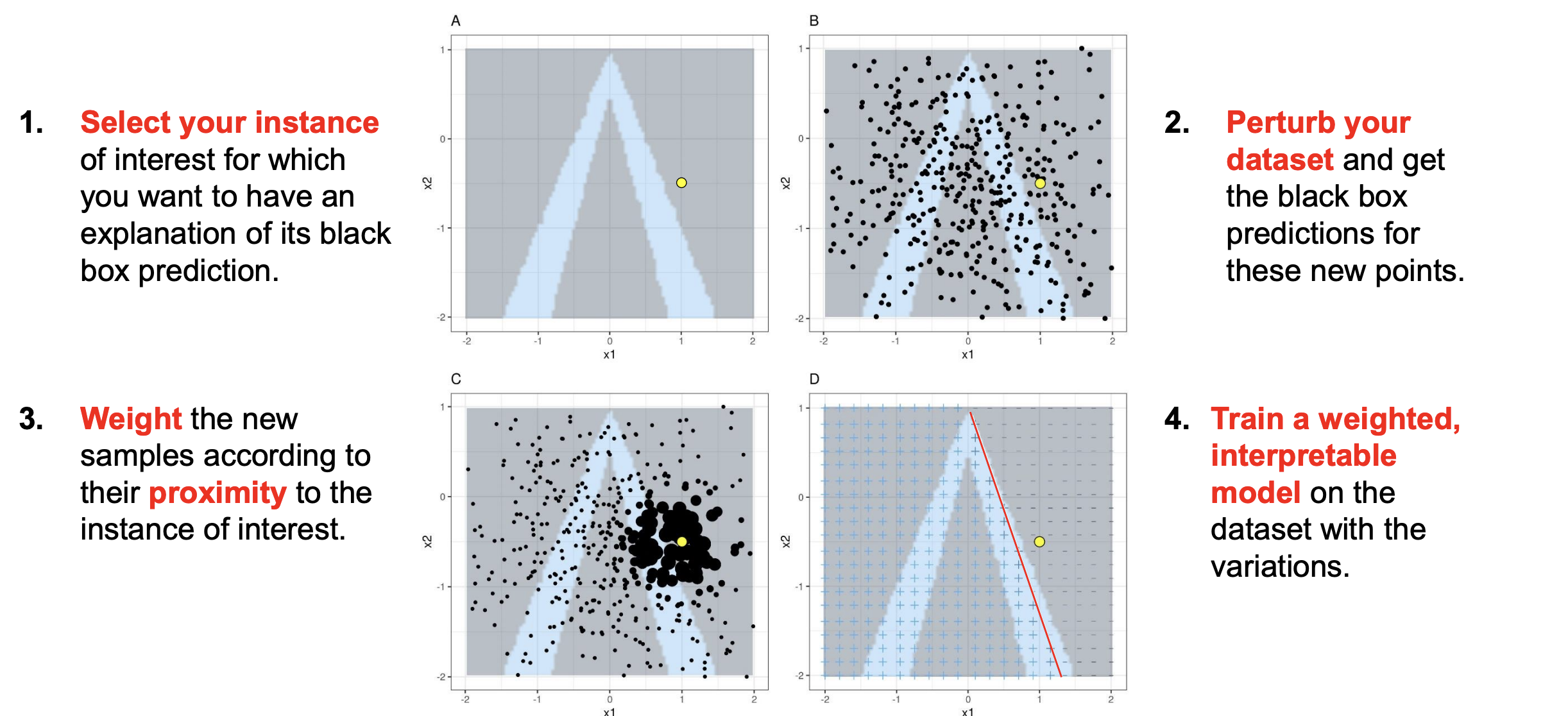
LIME
-
대표적인 Surrogate model을 만들어서 설명하는 XAI 방법 중에 하나.
-
Model agnostic, Local, Post-hoc, surrogate $$$\text{explanation}(x) = \arg\min_{g \in G} \left[ L(f, g, \pi_x) + \Omega(g) \right]$$
-
is the loss function comparing the explainable model to the original function .
-
is the proximity measure which defines the neighborhood around instance .
-
is a measure of the complexity of the model .
-
The explainable model could be a Lasso regression or a Decision Tree.
-
하나의 instance를 설명하기 위한 interpretable surrogate model을 만들고 그 모델을 해석함으로써 모델의 설명을 시도하는 방법
RISE (Randomized input sampling for explanation)
- Model agnostic, Local, Post-hoc, heatmap
-
- 원본 이미지에 random한 mask를 생성하여, 이를 통해서 기존 prediction에 변화량을 weight sum하여 중요한 영역을 찾아내는 방법

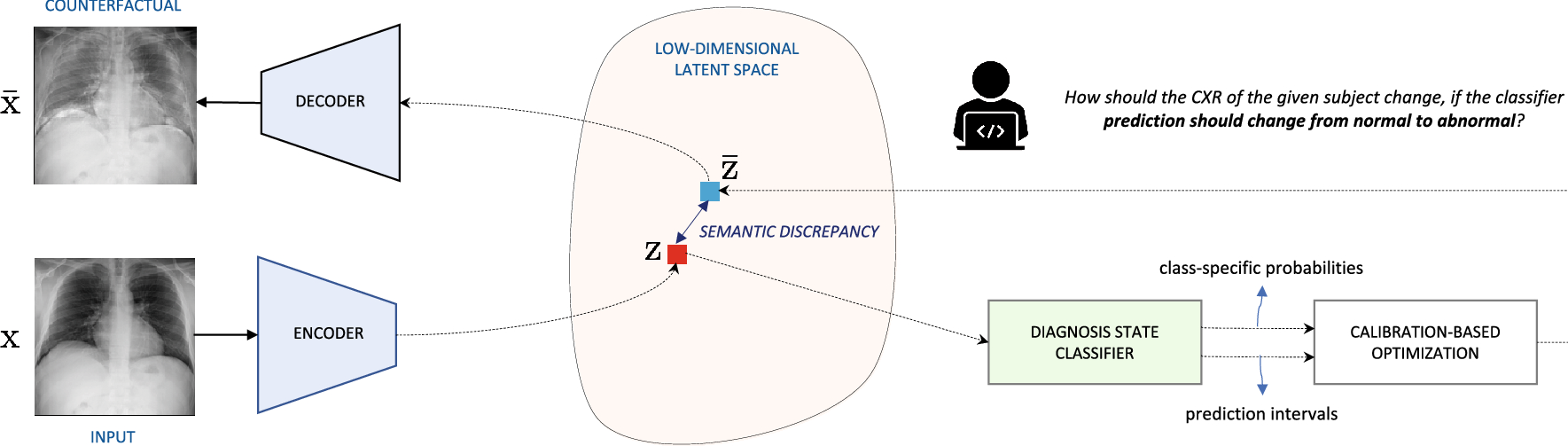
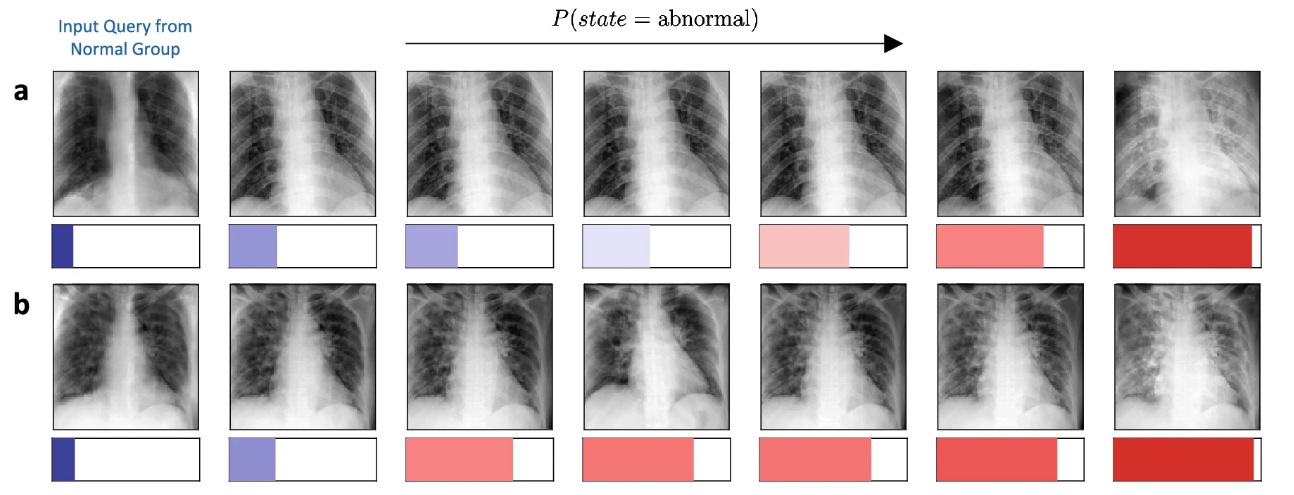
Counterfactual explanation
- Model agnostic, Local, Post-hoc, example
- 실제 input 데이터의 prediction이 바뀔만한 perturbation 주어서, 대조적인 predcition sample을 통해 모델을 해석하는 방법
- 정형데이터에서는 SHAP value를 사용하며, 비정형데이터에서는 generative model을 활용한 counterfactual가 발전하고 있음.
 (https://www.nature.com/articles/s41598-021-04529-5)
(https://www.nature.com/articles/s41598-021-04529-5)
Concept based
- 연구자가 확인하고 싶은 컨셉을 정의하고, 이를 모델이 내부적으로 활용하고 있는지를 확인함으로써 해석하는 방법
- Properties for concept-based explanation
- Meaningfulness: semantically meaningful on its own 개념이 스스로 의미를 가지고 있어야 한다는 것을 말합니다. 즉, 그 개념이 무엇인지 사람이 보고 바로 이해할 수 있어야 합니다. 예를 들어, ‘종양’이라는 개념은 의료 이미지 분석에서 중요하며, 스스로 의미가 있고, 사람들이 이해할 수 있는 개념입니다.
- Coherency: perceptually similar to each other while being different from examples of other concepts. 개념이 표현하는 예시들이 서로 비슷하면서도, 다른 개념의 예시들과는 확실히 구분될 수 있어야 한다는 것을 의미합니다. 예를 들어, ‘종양’이라는 개념에 속하는 이미지들은 서로 비슷한 특징을 공유하지만, ‘정상 조직’이라는 다른 개념의 이미지와는 확연히 다른 특징을 보여야 합니다. 이렇게 함으로써, AI가 해당 개념을 정확하게 인식하고 구분할 수 있게 됩니다.
- Importance: its presence is necessary for the true prediction of samples in that class. 개념의 존재가 해당 클래스의 샘플을 정확하게 예측하는 데 필수적이어야 한다는 것을 나타냅니다. 즉, 그 개념이 없으면 AI가 올바른 결정을 내리는 데 어려움을 겪을 수 있습니다. 예를 들어, ‘종양’이라는 개념은 암을 진단하는 AI 모델에서 매우 중요합니다. ‘종양’의 존재 여부가 진단 결과에 큰 영향을 미칠 수 있기 때문입니다.
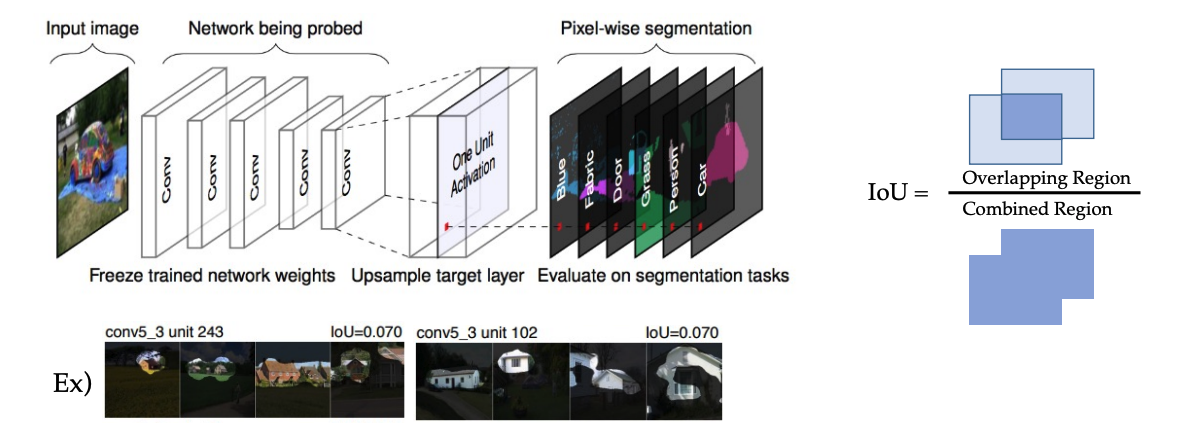
Network Dissection
- Model-specific, Local, Post-hoc, metric
- 각 convolution layer에서 feature map을 원본 크기로 upsampling함.
- 활성값을 설정하고, 각 conv feaure map을 0 또는 1의 binary로 만듬.
- 인간이 정의한 simentic segmentaion과 overlap하여 어떤 개념을 주로 보고 있는지를 추론
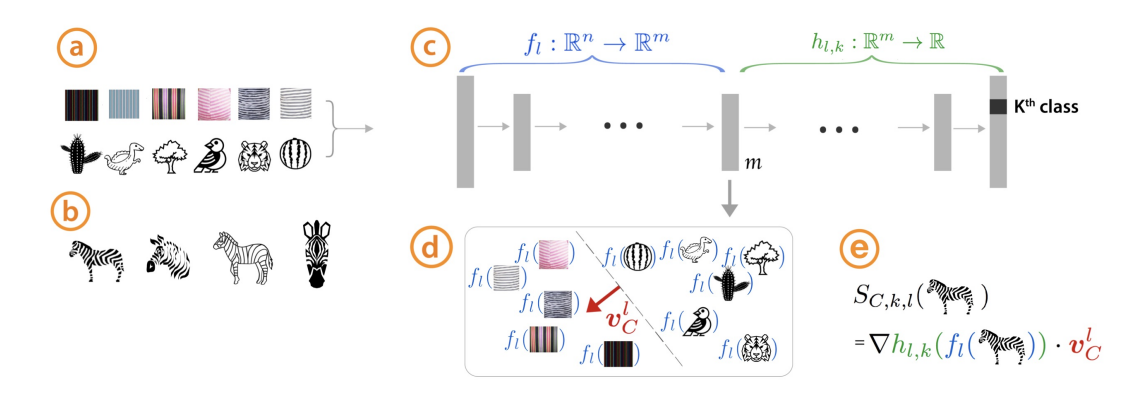
TCAV (Testing concept activation vector)
- Model-specific, Global, Post-hoc, metric
- 확인하고자하는 특정 개념을 정의하고, 이를 반영하는 concept데이터셋을 활용하여 모델을 해석하는 방법.
- 결과적으로 TCAV score를 통해서 모델에 우리가 확인하고자하는 개념이 활용되는지 정량적으로 평가함.
Attention based
(To be continue)
Evaluation of XAI

Content
- 정확성(Correctness): 설명이 설명하고자 하는 블랙박스 모델에 대해 얼마나 충실한지를 평가합니다. 모델의 추론을 정확히 반영하는지 확인하여 설명의 신뢰성을 강조합니다.
- 예시: 머신러닝 모델이 사진 속 고양이를 인식했다면, 정확성은 모델이 고양이의 특징(예: 귀, 눈)을 기반으로 판단했는지를 설명해야 합니다.
- 완전성(Completeness): 모델의 행동이나 추론을 얼마나 잘 설명하는지 측정합니다. 다음 두 가지로 나뉩니다:
- 추론 완전성(Reasoning-completeness): 설명이 모델의 내부 역학을 얼마나 잘 설명하는지 측정합니다.
- 출력 완전성(Output-completeness): 설명이 모델 출력을 얼마나 잘 설명하는지 측정합니다.
- 예시: 모델이 여러 특징을 사용해 결정을 내렸다면, 그 모든 특징이 설명에 포함되어야 합니다. 고양의 귀와 눈을 가지고 판단했다면, 설명 안에는 귀와 눈이 모두 있어야함.
- 일관성(Consistency): 동일한 입력이 동일한 설명을 생성하는지 평가하여, 설명 방법의 결정론적 특성과 구현 불변성을 강조합니다.
- 예시: 두 사용자가 동일한 데이터로 모델을 쿼리할 때, 둘 다 동일한 설명을 받아야 합니다.
- 연속성(Continuity): 입력의 소폭 변화가 설명에 큰 변화를 일으키지 않아야 하며, 설명 함수의 부드러움을 보장합니다.
- 예시: 사용자가 이미지의 픽셀을 약간 조정했을 때, 설명의 변화가 미미해야 합니다.
- 대조성(Contrastivity): 다른 결과나 이벤트와 비교하여 설명이 얼마나 구분되는지 평가합니다.
- 예시: “왜 이 이미지가 고양이로 분류되었는가?”와 “왜 이 이미지가 강아지가 아닌가?”에 대한 설명을 제공할 수 있어야 합니다.
- 공변량 복잡성(Covariate Complexity): 설명에 사용된 특징의 복잡성과 이해 가능성을 평가합니다.
- 예시: 고급 통계 대신 간단하고 직관적인 언어로 설명을 제공해야 합니다.
Representation
- 간결성(Compactness): 설명의 크기를 다루며, 인간의 인지 한계 내에서 이해할 수 있도록 간결함을 추구합니다.
- 예시: 필요한 정보만을 간략하게 제공하여 사용자가 쉽게 이해할 수 있어야 합니다.
- 구성(Composition): 설명의 형식, 조직, 구조를 고려하여 명확성을 높입니다.
- 예시: 사용자가 이해하기 쉬운 형식(예: 시각적 그래프)으로 정보를 제공해야 합니다.
- 신뢰도(Confidence): 설명에 확신 또는 다른 확률 정보가 포함되어 있는지, 그리고 그 정확성을 다룹니다.
- 예시: 모델이 결정에 대해 얼마나 확신하는지를 수치로 표현할 수 있어야 합니다.
User
- 상황적 맥락(Context): 설명이 사용자의 필요와 전문 지식 수준을 고려하는 정도를 평가합니다.
- 예시: 의료 분야 전문가에게는 전문 용어를 사용한 설명을, 일반 사용자에게는 간단한 언어로 설명을 제공해야 합니다.
- 일치성(Coherence): 기존의 배경 지식, 믿음 및 일반적인 합의와 얼마나 일치하는지 평가합니다.
- 예시: 설명이 사용자의 기존 지식과 일치하여, 설명이 합리적으로 느껴져야 합니다.
- 제어 가능성(Controllability): 사용자가 설명과 상호 작용하고, 제어하거나 조정할 수 있는 정도를 측정합니다.
- 예시: 사용자가 설명을 조정하여 자신에게 더 적합하게 만들 수 있어야 합니다.
Correctness (faithfulness)
- 설명의 결과가 정말 모델 예측에 있어서 중요한 부분이 맞았는지를 측정하는 지표

Deletion and Insertion
- heatmap으로 나온 중요도를 높은 순으로 지워가면서(채워가면서) model의 prediction 변화를 정량적으로 수치화하는 방법

Completeness

Sanity check
- 명백한 영역의 task를 두고 확인하는 방법
- 삼각형 맞추기 task를 주고, 모델의 설명이 정확히 삼각형의 영역을 덮고 있는지 확인하는 방법.
Robustness (continuity)
- 조금 다른 데이터에 대해서도 강건한 설명을 제공해야 함.

